Project Jupyter
Introducción
Jupyter es una aplicación web que permite crear y compartir documentos que contienen codigo 'vivo', ecuaciones, visualizaciones y texto.
La misma es muy utilizada como herramienta en contextos de Data Science, por las posibilidades que da para expresar informacion asi como la conexión posible mediante kernels a diferentes lenguajes.
Para mas información pueden visitar jupyter.org y para saber mas de sus origenes pueden remitirse a IPython Notebook
Objetivo
El objetivo de esta guía es realizar una instalación de Jupyter de forma local y realizar una configuracion para poder usar el kernel de spark con la instalación que realizamos localmente.
Esta instalación fue probada en un entorno de Ubuntu LTS.
Instalación
Instalacion de python-dev y pip
Suponemos que existe en el sistema una instalacion de python. Por esta razón instalamos herramientas de build y extensiones para python (para poder compilar algunas librerias) y pip, un popular manejador de paquetes.
apt-get install build-essential python-dev python-pip
Recomendamos realizar una actualizacion de pip a traves del comando
pip install --upgrade pip
Instalación de jupyter
Una vez instalado pip, lo usamos para instalar jupyter
pip install jupyter
y tambien la extension ipyparallel que se utiliza como interfaz para el manejador de kernels en la interfaz de jupyter
pip install ipyparallel
ipcluster nbextension enable
Iniciando el Jupyter Server
Para poder iniciar el server de jupyter, desde linea de comando deben ir al directorio en el cual van a querer guardar los notebooks y ejecutar el siguiente comando para levantar el server en todas las interfaces.
jupyter notebook --ip 0.0.0.0
Esto va a imprimir informacion sobre el notebook server en la consola, incluyendo la url de la aplicacion web. (http://0.0.0.0:8000)
Para poder utilizar jupyter desde un web browser accedan a http://0.0.0.0:8000
Para mas opciones de ejecucion pueden ver la siguente documentacion: http://jupyter.readthedocs.org/en/latest/running.html
Iniciando Jupyter Server con pyspark
Para contar con soporte de pyspark en jupyter, tendremos que configurar las siguientes variables de entorno en nuestro shell
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS=notebook
de esta forma le indicamos a pyspark que por default vamos a utilizar al iniciar pyspark como driver.
Para iniciar entonces jupyter notebook con soporte a spark tenemos que ejecutar
pyspark
El cual debería estar disponible como comando si completaron la guia de instalación de apache spark y configuraron correctamente los PATHs de apache spark correspondientes.
Al ejecutarse debería iniciarse pyspark y verse el log de jupyter server
ak @ nakata ~ % pyspark [0]
[I 17:59:06.045 NotebookApp] Serving notebooks from local directory: /Users/ak
[I 17:59:06.045 NotebookApp] 0 active kernels
[I 17:59:06.045 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/?token=da8bcb1f17866f98fda425f03efbdb7cdac72a41bcaa52a6
[I 17:59:06.045 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 17:59:06.046 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=da8bcb1f17866f98fda425f03efbdb7cdac72a41bcaa52a6
[I 17:59:06.438 NotebookApp] Accepting one-time-token-authenticated connection from ::1
[I 17:59:11.357 NotebookApp] Creating new notebook in
[I 17:59:12.454 NotebookApp] Kernel started: 39f4b4ce-99a1-4767-96f3-381fac95500e
En algunos sistema dependiendo de la configuración se abrirá un tab en su navegador ya mostrando la web-ui de jupyter notebook.
Para terminar de probar la instalación creen un notebook de tipo python como en siguiente screenshot.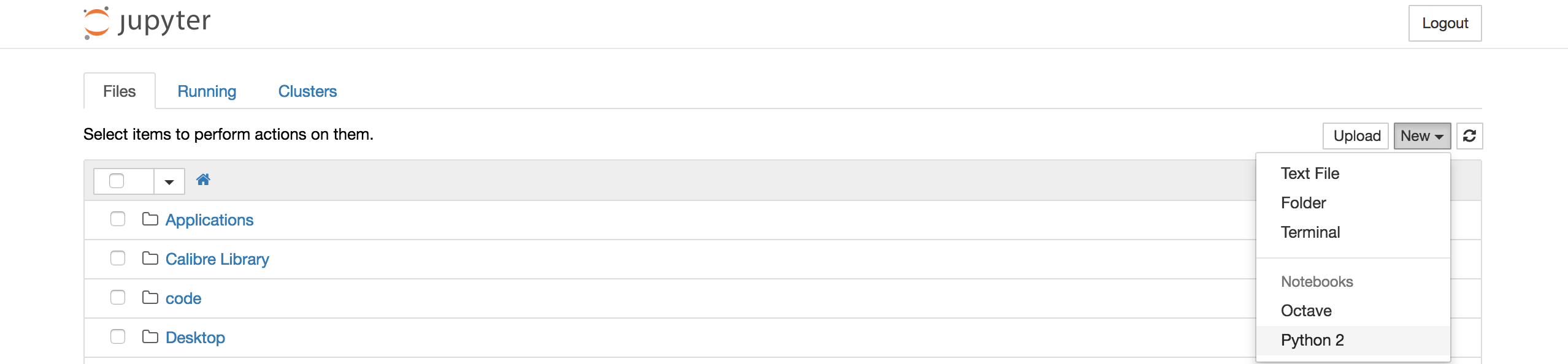
Una vez en el notebook especifico, pueden verificar la instalación verificando si la variable sc se encuentra definida como en el screenshot abajo.
Si queremos frecuentemente usarlo de esta forma podemos guardar adicionar esas lineas de setup de variables de entorno en nuestro .bashrc o .profile.